Разработка метода извлечения пиков из масс-спектра MALDI-TOF высокого разрешения с помощью машинного обучения с упором на форму пика и его применение к анализу синтетических полимеров [Приложение MALDI]
MSTips №352
Времяпролетный масс-спектрометр с лазерной десорбцией/ионизацией с использованием матрицы (MALDI-TOFMS) является мощным инструментом для анализа полимеров. MALDI-TOFMS высокого разрешения облегчает идентификацию серий полимеров по элементному составу повторяющихся звеньев и концевых групп, а также позволяет рассчитать молекулярно-массовое распределение полимеров по распределению ионной интенсивности. В реальном промышленном анализе материалов анализируются смеси полимеров с различным распределением молекулярной массы и концевыми группами, и используется анализ дефекта массы Кендрика (KMD), который позволяет получить обзор сложных масс-спектров. KMD-анализ может визуализировать количество и относительное количество серий полимеров, содержащихся в комплексном масс-спектре, потому что серия полимеров визуализируется как прямая линия на диаграмме, называемой графиком KMD. Еще одна особенность заключается в том, что он облегчает обнаружение следов компонентов. Поскольку график KMD создается путем извлечения пиков из масс-спектра, важно правильно различать пики, подлежащие анализу, и пики шума. Масс-спектры MALDI-TOFMS часто показывают шумовые пики, в которых интенсивность ионов уменьшается экспоненциально с увеличением м / г. Эти пики широкие, искаженной формы и плохо воспроизводимы. В масс-спектре, измеренном с помощью MALDI-TOFMS высокого разрешения серии JMS-S3000 «SpiralTOF™», анализируемые пики имеют узкую ширину, что позволяет визуально отличить их от неинформативных пиков. Однако выполнение идентификации по всему спектру масс, включая второстепенные пики, требует много времени и неэффективно. При обычном автоматическом определении пика значение площади пика используется в качестве интенсивности ионов. Поэтому, когда широкий шумовой пик имеет ту же высоту, что и анализируемый пик, его может быть трудно равномерно отсортировать с помощью порогового значения, поскольку интенсивность ионов становится выше. На рис. 1 показан масс-спектр профиля, анализируемые пики и шумовые пики после общего определения пиков. В списке пиков анализируемые пики окрашены в красный цвет, а шумовые пики — в зеленый. Слабые шумовые пики наблюдались через каждые 1 мкм в спектре профиля. В спектре профиля анализируемые пики могут быть идентифицированы на основе ширины пика, но после обнаружения пика интенсивность ионов (площадь пика) шумовых пиков становится относительно большой, что затрудняет идентификацию анализируемых пиков. . Чтобы решить эту проблему, в этом отчете описывается разработка метода определения того, является ли пик в спектре масс целевым пиком для анализа или пиком шума, с использованием машинного обучения с контролируемыми данными, который фокусируется на форме пика.
Эксперимент
Для получения данных для машинного обучения были приготовлены полиэтиленгликоли (ПЭГ) со средней молекулярной массой 400, 600, 1000 и 2000 в концентрации 10 мг/мл, а затем смешаны с 1:1:2:4 (об/об/об/об/мл). v) отношение (смесь ПЭГ). Кроме того, готовили разбавленную в 100 раз смесь ПЭГ в виде смеси ПЭГ с низкой концентрацией. В качестве матрицы использовали DCTB (10 мг/мл), а в качестве катионизатора использовали трифторацетат натрия (1 мг/мл). Масс-спектры были получены с использованием JMS-S3000 «SpiralTOF™-plus» в режиме положительных ионов SpiralTOF. Шумоподавление машинного обучения реализовано в msPeakFinder. Анализ KMD был выполнен с помощью msRepeatFinder.
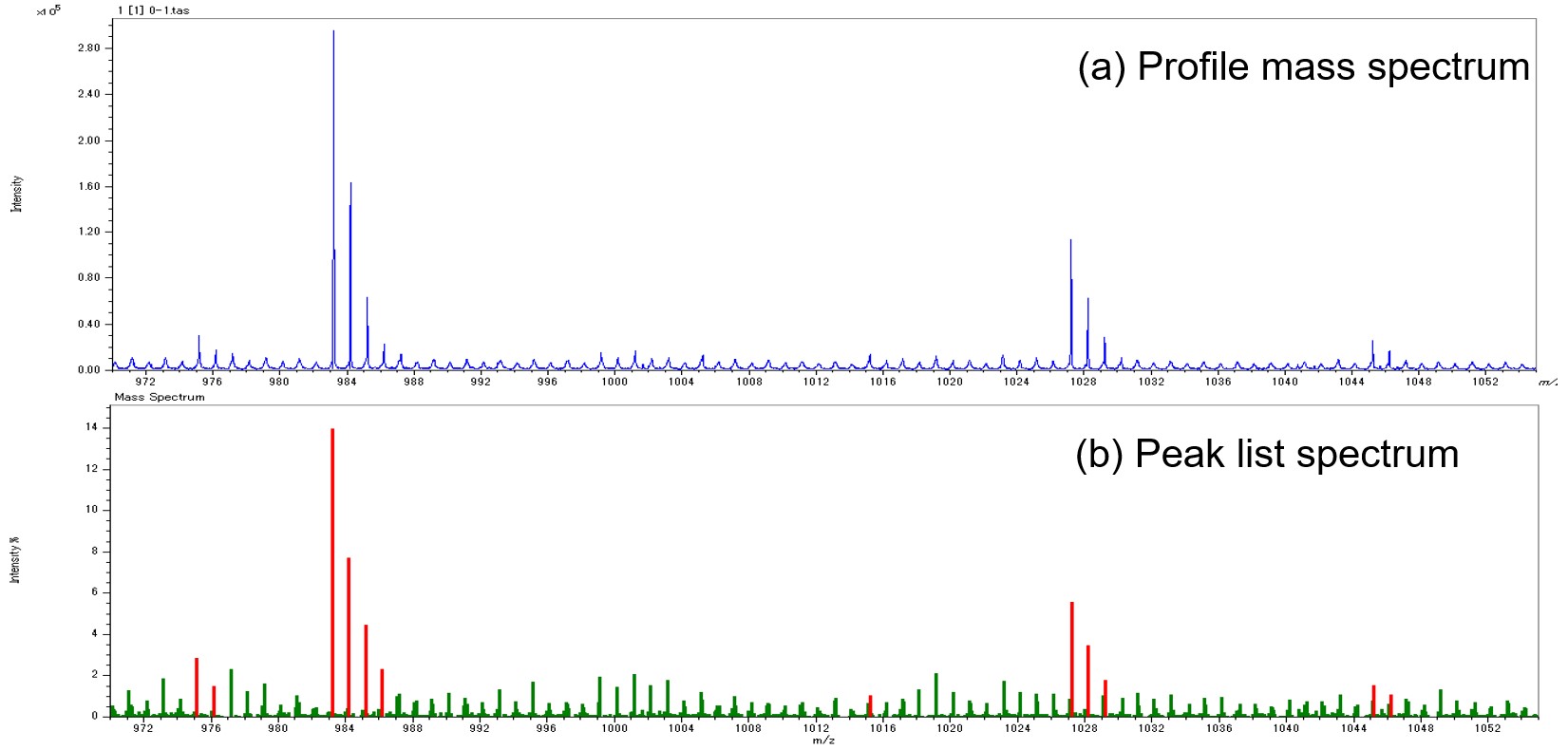
Рисунок 1 Профиль масс-спектра MALDI-TOFMS высокого разрешения (a) и спектр списка пиков с использованием обычного метода обнаружения пиков.
Метод машинного обучения
Для машинного обучения мы использовали условную генеративно-состязательную сеть (cGAN). Поскольку cGAN выводит сгенерированные данные в соответствии с входными данными условий, это можно рассматривать как преобразование данных условий в сгенерированные данные. Этот метод основан на концепции ввода наблюдаемого спектра масс и вывода спектра псевдомассы с удаленными шумовыми пиками и применения его для удаления шумовых пиков. На рис. 2 показана блок-схема процедуры создания модели машинного обучения для этого метода. На блок-схеме желтый фон — это вмешательство человека, а зеленый — автоматическое. Во-первых, мы получили масс-спектр смеси ПЭГ для обучающих данных (рис. 3а). После того, как полученный масс-спектр был подвергнут детектированию пиков обычным методом и был создан список пиков, пики, подлежащие анализу, были определены и выделены экспертом на основе формы пика (красная стрелка на рис. 3b). Пики для анализа были установлены на постоянную высоту независимо от наблюдаемой интенсивности ионов, а форма пика была создана с распределением Гаусса для создания псевдомассового спектра (рис. 3c). В этом методе полученный масс-спектр и псевдомассовый спектр объединялись и использовались в качестве исходных данных для обучающих данных. Теперь требуется время и усилия, чтобы получить большое количество масс-спектров, чтобы увеличить количество обучающих данных. Поэтому мы создали в общей сложности 1,600 пар обучающих данных из одних исходных данных, разделив исходные данные каждые 1,024 точки и пять раз изменив начальную точку деления. Модель машинного обучения была создана с использованием обучающих данных, созданных таким образом. Фигура. 4 показана концептуальная схема. Полученный масс-спектр преобразуется генератором в псевдомасс-спектр. Качество генератора было улучшено за счет различения комбинации этого измеренного спектра масс и псевдомасс-спектра, преобразованного через генератор, и комбинации измеренного спектра масс и псевдомасс-спектра обучающих данных с помощью дискриминатора.
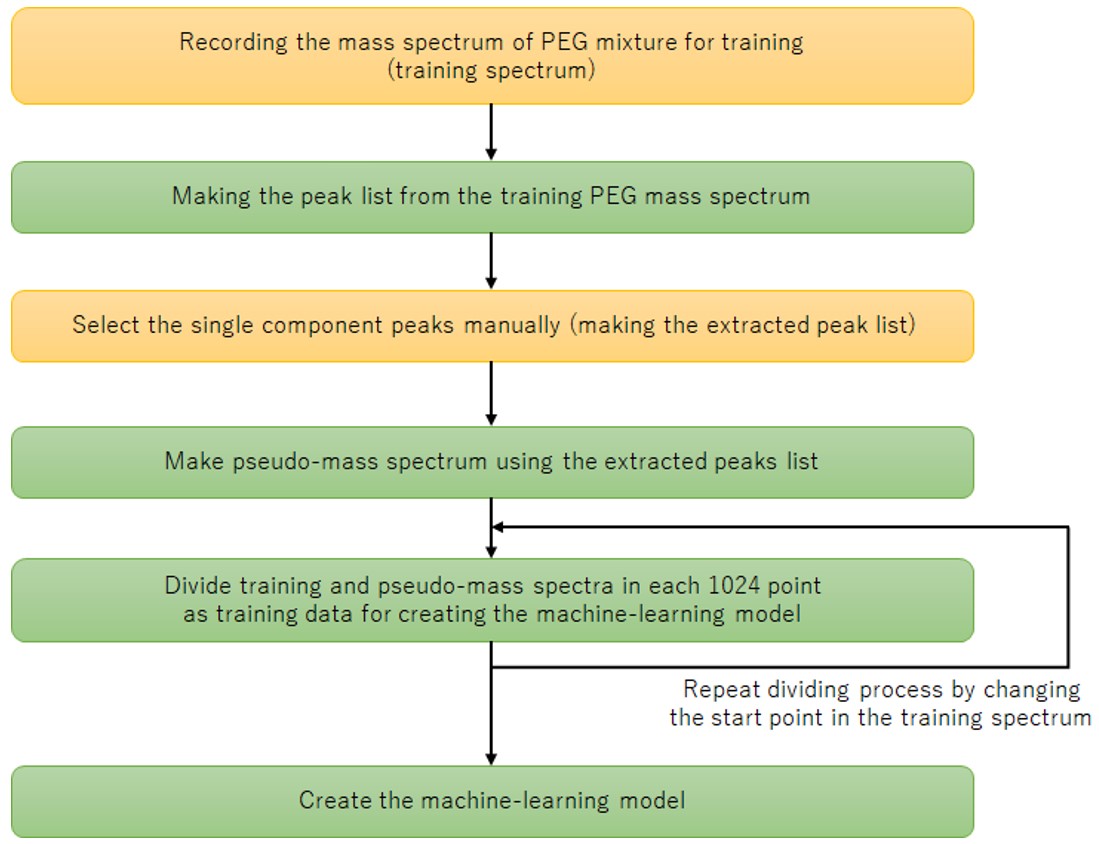
Рис. 2 Блок-схема создания модели машинного обучения.
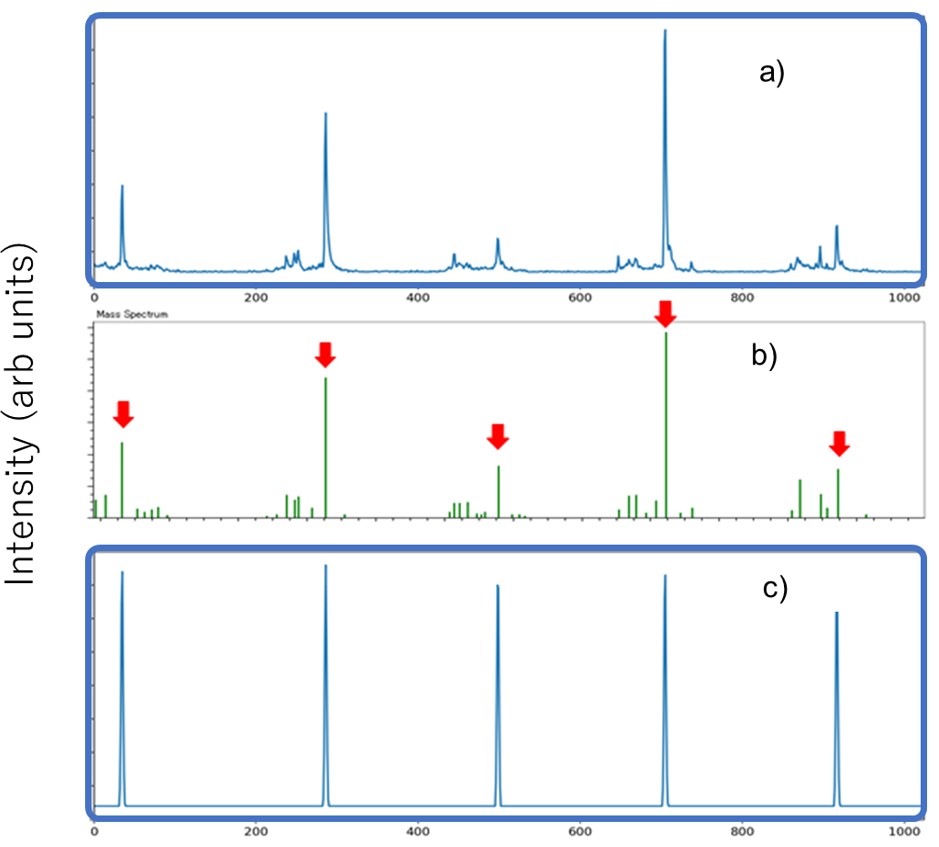
Рисунок 3 Взаимосвязь между профилем масс-спектра (а), списком пиков (б) и псевдомасс-спектром (в).
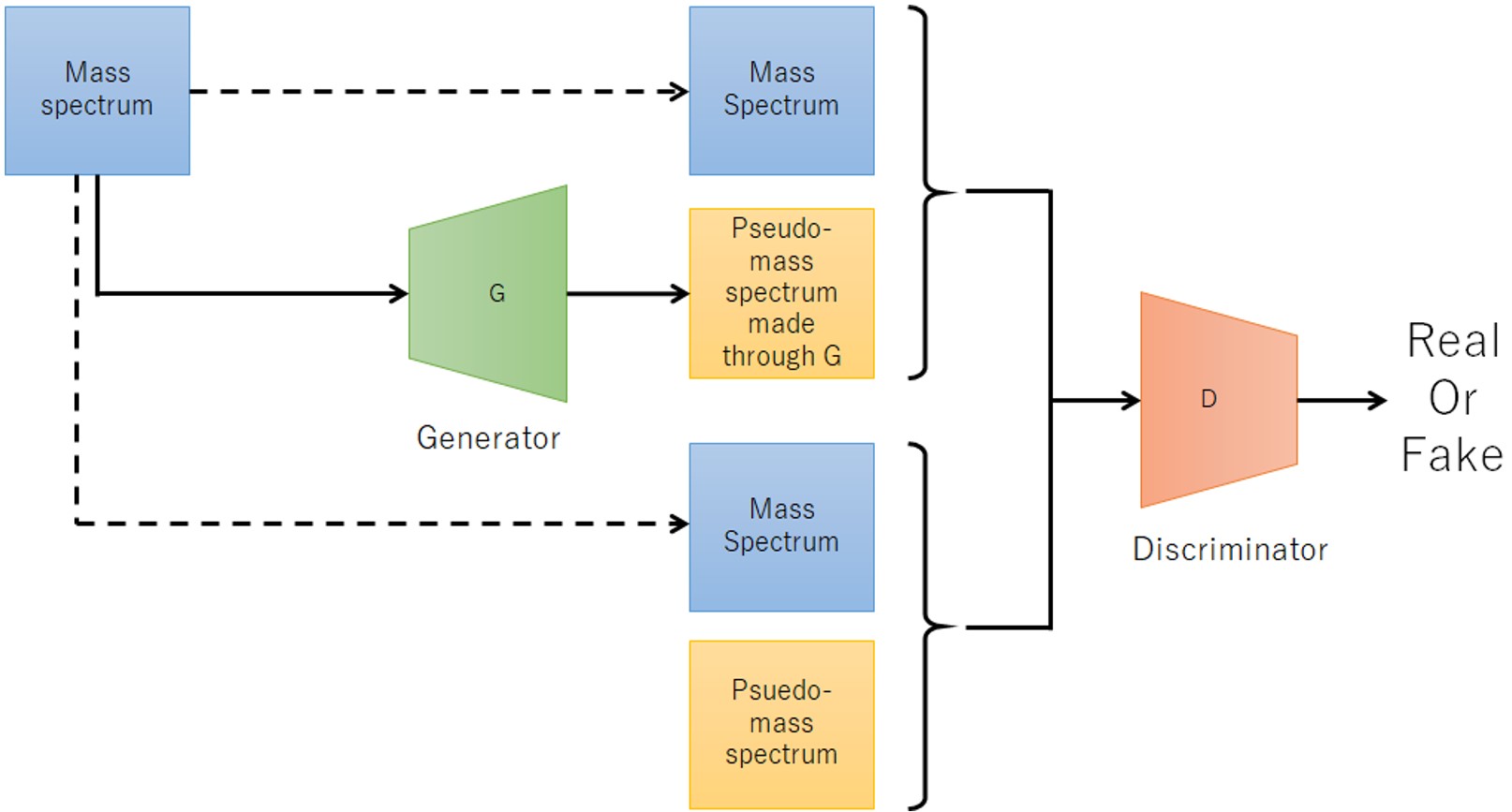
Рисунок 4 Схема создания модели машинного обучения с использованием cGAN.
Проверка и применение модели машинного обучения
Далее показана процедура фактического удаления шума с использованием сгенерированной модели машинного обучения (рис. 5). На блок-схеме желтый фон — это вмешательство человека, а зеленый — автоматическое. Полученный масс-спектр подвергается детектированию пиков традиционным методом, и параллельно с этим он делится на 1,024 точки и преобразуется в псевдомасс-спектры с использованием модели машинного обучения пиков, определенных традиционным методом, только пики, которые соответствуют позиции пиков псевдомассового спектра остаются, и генерируется список пиков с удаленным шумом. Другими словами, м / г и интенсивность ионов в списке пиков, извлеченном этим методом, такие же, как и в обычном методе. Здесь мы попытались удалить шумовые пики из масс-спектра смеси ПЭГ, который использовался для создания обучающих данных. Результаты суммированы в таблице 1. В масс-спектре смеси ПЭГ обычным способом было обнаружено всего 4,390 пиков. Среди них 1,265 пиков в левом верхнем углу и 3,105 пиков в правом нижнем углу (99.5% от общего числа) соответствуют результатам суждений, сделанных моделью машинного обучения, с суждениями, сделанными вручную при создании обучающих данных. 14 пиков в правом верхнем углу были определены как пики для анализа при создании модели машинного обучения, но моделью машинного обучения они были определены как пики шума. Было подтверждено, что формы этих пиков были слегка искажены и их трудно оценить даже эксперту. Шесть пиков в левом нижнем углу были определены как шумовые пики при создании обучающих данных, но были определены как пики для анализа с помощью модели машинного обучения. Было подтверждено, что это было вызвано человеческим фактором при подготовке данных для обучения. После этого снова было выполнено машинное обучение с обучающими данными, которое исправило эту ошибку. Мы считаем, что эффективно проверять модель с помощью спектра масс, который использовался для создания модели машинного обучения. Наконец, выделение пиков было выполнено с использованием масс-спектра ПЭГ с низкой концентрацией, и результаты, преобразованные в график KMD, показаны на рисунке 6. Рисунок 6a представляет собой измеренный масс-спектр, а рисунок 6b представляет собой график KMD. Красные точки на графике KMD были определены как пики для анализа с помощью машинного обучения, а зеленые точки были определены как пики шума. Из этого результата видно, что серии ПЭГ хорошо визуализируются при удалении шума, особенно в области м / г <1,500.
Обзор
Как описано выше, мы смогли показать, что анализ КМД может быть выполнен более эффективно путем удаления шумовых пиков, которые часто наблюдаются в низкочастотных диапазонах.м / г регион из данных MALDI-TOFMS высокого разрешения с использованием модели машинного обучения.
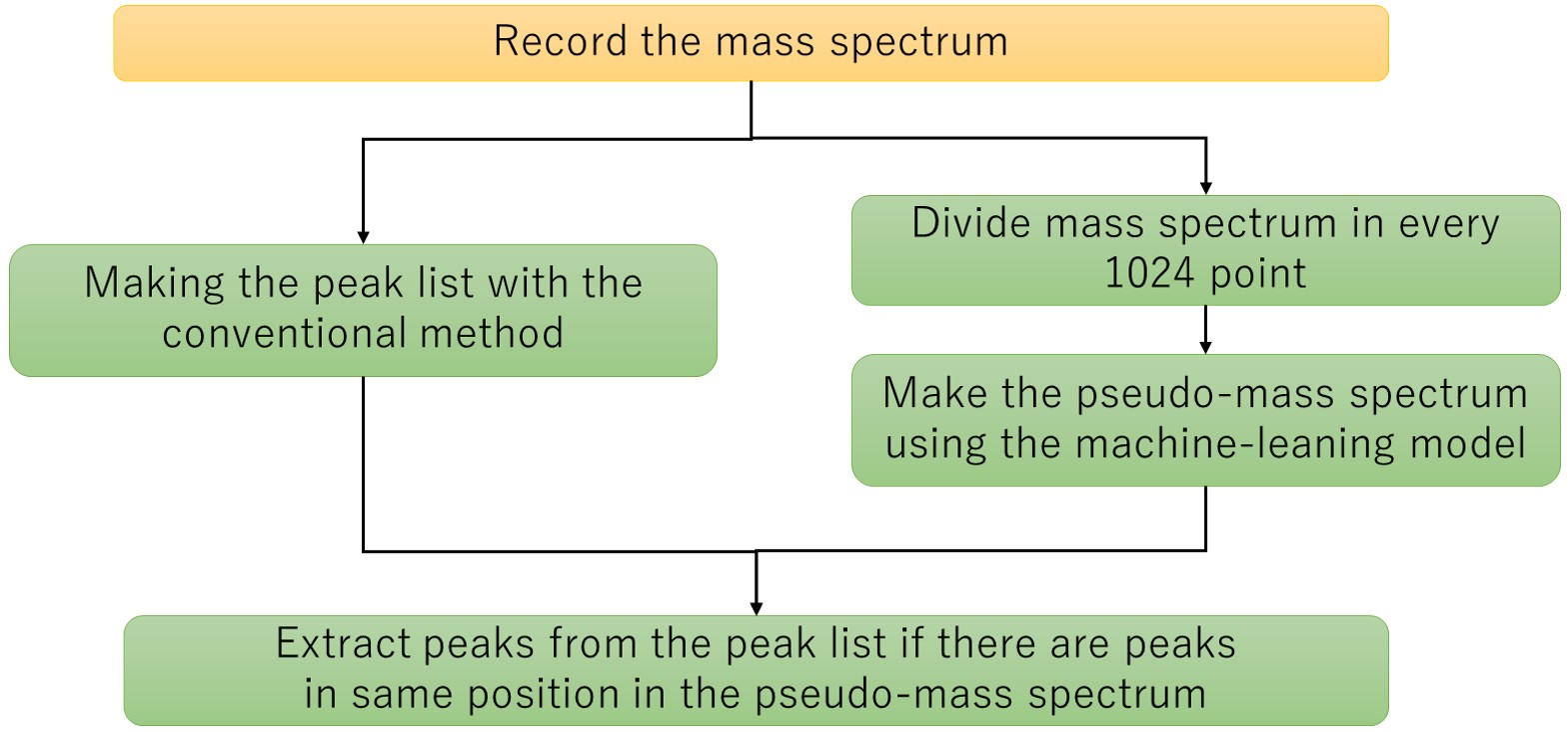
Рис. 5. Блок-схема создания списка извлеченных пиков с помощью модели машинного обучения.

Таблица 1. Сравнение списков пиков смеси ПЭГ, используемых в качестве обучающих данных, и списков, извлеченных моделью машинного обучения.
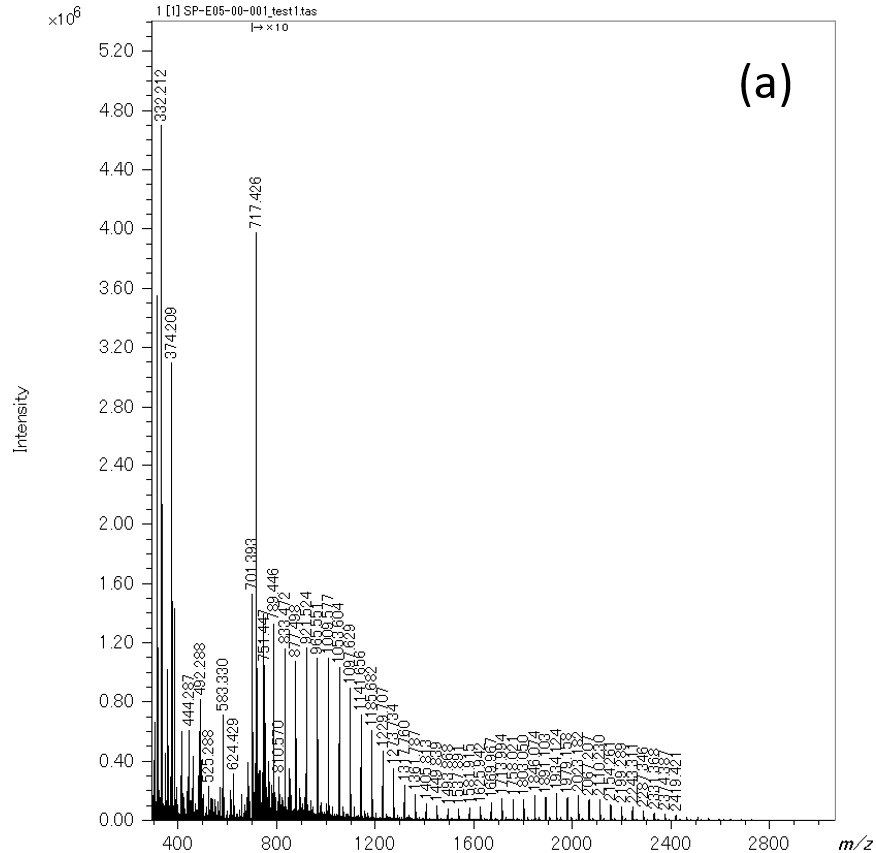
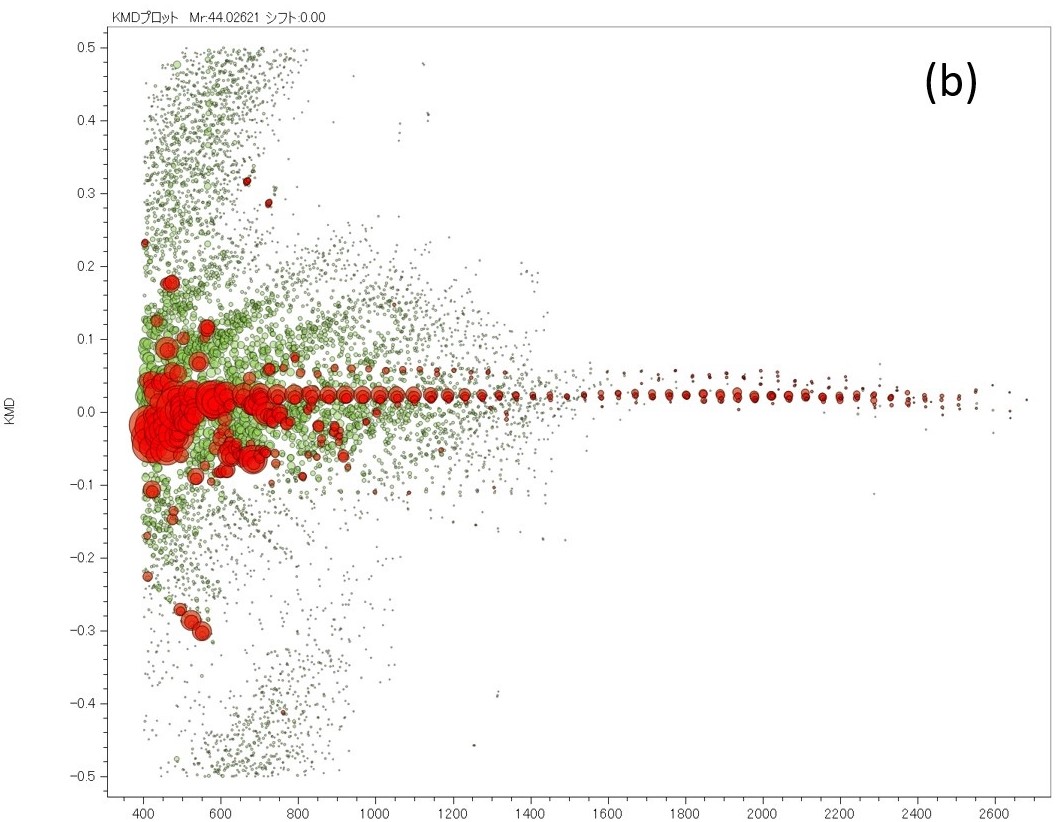
Рис. 6. Масс-спектр смеси ПЭГ с низкой концентрацией (а) и график KMD извлеченного списка пиков (красный) и списка шумов (зеленый), разделенных моделью машинного обучения.
Решения по областям применения
Вы медицинский работник или персонал, занимающийся медицинским обслуживанием?
Нет
Напоминаем, что эти страницы не предназначены для предоставления широкой публике информации о продуктах.